


一个会看、会听、会思考的智能透镜,还能当开发板和手电筒用
引言
Mirror-Mirror 项目旨在构建一个软硬件完全开源的智能“透镜”设备——它既能通过摄像头和 YOLO 实现实时物体识别,又能借助大模型 API 进行自然语言交互,同时还可作为 ARM 开发板、便携电源、小音箱或手电筒使用。名称 “Mirror Mirror” 取自 Mili 乐队的同名歌曲,其空灵的意境呼应了设备“镜像”世界与自我对话的理念;而功能概念则源于 《神秘时代》模组中的“魔导透镜”,正如透镜能揭示物品的奥秘,Mirror-Mirror 试图通过视觉与语音技术“揭示”周围环境的信息。
本文将详细介绍 Mirror-Mirror 的硬件设计思路、软件系统架构、核心功能的实现代码,并提供完整的开源资料索引,方便开发者复刻与二次开发。
硬件设计:从开发板到一体化便携终端
核心平台:全志 H618 + 7 寸触摸屏
主控采用全志 H618 开发板,该芯片基于 ARM Cortex-A53 64 位架构,主频最高 1.5GHz,集成 Mali-G31 GPU,支持 4K 视频解码,可同时负担 YOLO 目标检测推理与语音交互任务。我选择了一块市售的 H618 核心板,将其固定在底板上。显示部分选用一块 7 英寸触摸屏(分辨率 1024×600,带 HDMI 驱动板和 USB 触摸接口),提供直观的交互界面。

电源管理:模块化设计与智能监控
为实现便携使用,设计了独立的电源管理模块,强调模块化与安全性:
- 电池:一块 5000mAh 3.7V 锂电池直接焊接于电源模块,确保连接可靠。
- 接口:模块提供 5V Type-C 输入/输出(支持双向 PD 快充)及一个 USB-A 输出口,既可为设备充电,也可使设备作为充电宝对外供电。
- 监控:电源模块自带 LED 7 段数码管,通过硬件直连实时显示剩余电量百分比与功耗(单位:瓦特,W)。该显示无需软件参与,由电源管理芯片直接驱动,保证了低功耗和即插即用的可靠性。侧面设有一物理按键,用于一键开关机。
- 模块化设计优势:
- 独立运作:电源模块可单独工作,与电池组成一个 5000mAh 的移动电源。
- 直通供电:若无需电池,可直接以 5V 适配器接入开发板供电口,绕过电源模块,适用于固定场景。


接口扩展:丰富的连接能力
H618 主板原生接口有限,通过从主板 Type-C 口引出的扩展板,实现了以下接口:
- 3×USB-A + 1×USB-C:连接各类外设。
- 3.5mm 耳机口:音频输出。
- TF 卡槽 & SD 卡槽:扩展存储或直读相机卡。
此外,利用 USB-A 接口制作了若干3D 打印外壳的周边设备:
- USB 扬声器+麦克风:即插即用的音频模块,用于语音交互。
- USB 灯:手电筒/小夜灯功能,直接插入 USB 口即可点亮,无需额外控制电路。
- USB 摄像头:YOLO 视觉识别输入(也可用开发板自带 CSI 摄像头,但 USB 方案通用性更佳)。
- USB 有线网卡:补充 WiFi/BT 的稳定有线网络连接。
所有外壳均通过 3D 打印制作,结构紧凑,将主板、屏幕、电池、电源模块及扩展板整合为一体,正面仅露出屏幕与开关按键,侧面留有接口开口。



软件实现:Debian 定制 + YOLO + 大模型 API
操作系统:轻量级 Debian Bookworm
为 H618 编译了预装个性化软件包的 Debian 系统(arm64 架构),版本为 Debian bookworm。内核启用必要驱动(触摸屏、音频、电源管理),并预装以下软件栈:
- Python 3.11 + OpenCV + PyTorch(用于 YOLO)
- 音频服务(PulseAudio)
- 网络管理工具
- 开发工具链(gcc、make、git 等),使设备可直接作为 ARM 开发板进行原生编译。
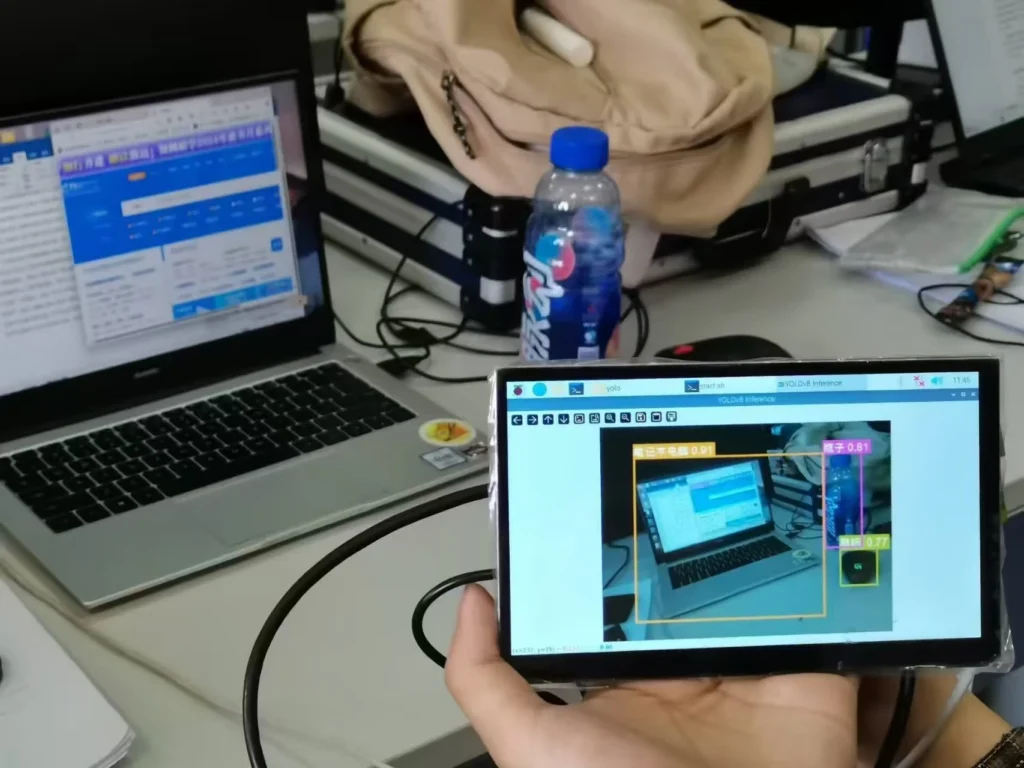
视觉核心:YOLO 通用目标检测
实时物体识别基于 YOLOv5(或 YOLOv8)轻量版,通过 ONNX Runtime 优化,在 H618 上可达约 10–15 FPS(输入尺寸适配屏幕分辨率 1024×600)。处理流程如下:
- 从 USB 摄像头捕获帧。
- 将帧直接缩放至屏幕分辨率 1024×600(保持全屏显示,无填充),送入模型推理。
- 后处理过滤低置信度检测,得到位于屏幕坐标系下的边界框。
- 将检测框绘制在缩放后的图像上,并实时显示于屏幕。
检测结果可通过本地 TTS(如 espeak)播报,或作为上下文输入到大模型。
下面是使用 Python 和 ONNX Runtime 进行 YOLOv5 推理的核心代码(简化版,完整代码见 GitHub):
import cv2
import numpy as np
import onnxruntime as ort
class YOLOv5:
def __init__(self, model_path, conf_thres=0.5, iou_thres=0.45):
self.session = ort.InferenceSession(model_path)
self.conf_thres = conf_thres
self.iou_thres = iou_thres
self.input_name = self.session.get_inputs()[0].name
self.class_names = ['person', 'bicycle', 'car', ...] # COCO 类别
self.target_width = 1024 # 屏幕宽度
self.target_height = 600 # 屏幕高度
def preprocess(self, img):
# 直接缩放至屏幕分辨率(1024x600)
img_resized = cv2.resize(img, (self.target_width, self.target_height))
# 转换为模型输入格式:CHW,归一化,添加batch维度
img_input = img_resized.transpose(2, 0, 1)[np.newaxis, ...].astype(np.float32) / 255.0
return img_input, img_resized # 返回缩放后的图像用于后续绘制
def postprocess(self, outputs):
# outputs shape: (1, 25200, 85) for YOLOv5
predictions = np.squeeze(outputs[0])
# 过滤低置信度
mask = predictions[:, 4] > self.conf_thres
predictions = predictions[mask]
if len(predictions) == 0:
return []
# 类别置信度
class_conf = np.max(predictions[:, 5:], axis=1)
class_pred = np.argmax(predictions[:, 5:], axis=1)
# 组合边界框 (cx, cy, w, h) 坐标,此时坐标值范围是 [0, 1](相对于输入尺寸)
boxes = predictions[:, :4]
# 将 cx,cy,w,h 转换为 xyxy 格式,并映射到屏幕像素坐标
boxes[:, 0] = (boxes[:, 0] - boxes[:, 2] / 2) * self.target_width
boxes[:, 1] = (boxes[:, 1] - boxes[:, 3] / 2) * self.target_height
boxes[:, 2] = (boxes[:, 0] + boxes[:, 2] * self.target_width)
boxes[:, 3] = (boxes[:, 1] + boxes[:, 3] * self.target_height)
# NMS 去除冗余框
indices = cv2.dnn.NMSBoxes(boxes.tolist(), class_conf.tolist(), self.conf_thres, self.iou_thres)
result = []
for i in indices.flatten():
result.append({
'bbox': boxes[i].astype(int),
'class_id': class_pred[i],
'class_name': self.class_names[class_pred[i]],
'confidence': class_conf[i]
})
return result
def detect(self, img):
input_data, display_img = self.preprocess(img)
outputs = self.session.run(None, {self.input_name: input_data})
dets = self.postprocess(outputs)
return dets, display_img # 返回检测结果和可直接显示的图像
使用时,循环读取摄像头帧,调用 detect 方法获得检测结果和已缩放的图像,然后在图像上绘制边界框并显示到屏幕即可。由于图像尺寸已适配屏幕,无需额外坐标变换,大幅简化了显示逻辑。
语音交互:大模型 API 集成
当插入 USB 语音模块(扬声器+麦克风)后,设备可切换为语音助手模式。采用离线唤醒词 + 云端大模型方案:
- 使用 Porcupine 或 Snowboy 实现本地唤醒(如“Hey Mirror”)。
- 唤醒后录制用户语音,调用大模型 API(例如 ChatGPT、Claude 或国内大模型)进行自然语言处理。
- 返回结果通过本地 TTS 合成语音播放。
该机制支持多模态对话:例如用户问“镜子里有什么?”,系统可结合 YOLO 识别结果生成描述性回答。
唤醒词检测(Porcupine 示例)
import pvporcupine
import pyaudio
import struct
porcupine = pvporcupine.create(keywords=["mirror"]) # 需要获取AccessKey
pa = pyaudio.PyAudio()
audio_stream = pa.open(
rate=porcupine.sample_rate,
channels=1,
format=pyaudio.paInt16,
input=True,
frames_per_buffer=porcupine.frame_length)
print("Listening for wake word 'mirror'...")
while True:
pcm = audio_stream.read(porcupine.frame_length)
pcm = struct.unpack_from("h" * porcupine.frame_length, pcm)
if porcupine.process(pcm) >= 0:
print("Wake word detected!")
# 触发语音识别和大模型调用
break
语音识别与 TTS
语音识别可选用本地 Vosk 或云服务(如 Azure Speech)。为简化,我们采用在线服务(例如 OpenAI Whisper API)或本地离线识别(Vosk)。TTS 使用 espeak 或更高质的 piper TTS。
调用大模型 API(OpenAI 示例)
import openai
import json
openai.api_key = "your-api-key"
def query_llm(prompt):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=200
)
return response.choices[0].message.content
# 结合视觉信息的示例
def answer_with_vision(user_question, yolo_objects):
objects_desc = ", ".join([obj['class_name'] for obj in yolo_objects])
prompt = f"User asks: {user_question}. Currently I see: {objects_desc}. Please answer the question based on what I see."
return query_llm(prompt)
完整的语音交互循环
def voice_interaction_loop():
while True:
if detect_wake_word():
# 录制语音(例如用 pyaudio 录制 5 秒)
audio = record_audio(duration=5)
# 语音识别
text = speech_to_text(audio)
if not text:
continue
# 获取当前 YOLO 检测结果(全局变量或通过队列共享)
current_objects = yolo_results.get_latest()
# 构造 Prompt 并调用大模型
answer = answer_with_vision(text, current_objects)
# TTS 播放
text_to_speech(answer)
此循环可作为后台服务运行,与 YOLO 实时检测线程并行。
其他实用功能
- 手电筒:通过将 USB 灯直接插入设备的 USB-A 口实现,即插即用,无需软件控制。
- 小音箱:通过蓝牙或音频线连接手机播放音乐,或使用预装的 mpv 播放本地音频。
- ARM 开发板模式:用户可通过 SSH 登录,进行代码编译、测试,甚至运行 Docker 容器。设备预装了常用的开发工具和 Docker CE,便于二次开发。

扩展应用:C-SORTING 照片智能管家
除了视觉与语音交互,Mirror-Mirror 还能变身为摄影师的随身整理助手——由笔者开发的另一款软件 C-SORTING 恰好能完美融入这一硬件平台。C-SORTING 是一款基于 PyQt6 的全离线照片视频自动分类工具,能根据 EXIF 信息中的拍摄时间和 GPS 坐标,将存储卡中杂乱无章的文件快速整理为“年-月-日”或“城市名称”的清晰目录。将 C-SORTING 部署在 Mirror-Mirror 上,可谓天作之合:
- 即插即用的硬件适配:Mirror-Mirror 侧面自带的 SD 卡槽和 TF 卡槽,可直接插入相机存储卡;若卡型不匹配,还可通过 USB-A 口外接读卡器。无需额外转接,即可读取原始素材。
- 全平台离线运行:C-SORTING 采用 Python + PyQt6 开发,完全离线运行,所有地理编码依赖本地预置的城市坐标库,不泄露隐私。Mirror-Mirror 预装的 Debian 系统(arm64)能直接运行 C-SORTING,无需修改代码,且触摸屏操作与鼠标点击同样流畅。
- 便携场景的完美闭环:户外拍摄归来,在营地或车上即可掏出 Mirror-Mirror,插入 SD 卡,打开 C-SORTING,几分钟内完成数百张照片的自动归档。5000mAh 电池保证数小时整理续航,无需依赖电脑或网络。
- 未来可扩展的智能分类:利用 Mirror-Mirror 的 YOLO 视觉能力,未来还可为 C-SORTING 增加“场景识别”分类模式(如自动区分人像、风景、宠物),让整理更加智能化。
两个项目均由笔者开发,它们的无缝结合展现了从软件到硬件的完整创作闭环。开发者已在 GitHub 开源 C-SORTING 项目,只需在 Mirror-Mirror 上克隆仓库并安装依赖,即可享受私密、高效的离线媒体管理体验。这进一步印证了 Mirror-Mirror 作为全能移动终端的潜力——不仅是观察世界的透镜,更是整理数字生活的管家。
功能场景展示
- 智能家居中控:置于玄关,识别访客与物品,语音查询天气、日程。
- 开发伴侣:作为桌面副屏,实时显示 YOLO 调试输出,同时可编译代码。
- 移动助手:户外露营时,USB 灯提供照明,摄像头识别动植物,语音查询百科知识。
- 教育工具:演示 AI 视觉与语音原理,支持学生编写 Python 脚本扩展功能。
未来展望
当前 Mirror-Mirror 仍为原型阶段,后续计划包括:
- 优化电源管理,实现更低功耗待机(如深度睡眠,唤醒后快速恢复)。
- 集成更多传感器(温湿度、红外等),增强环境感知能力。
- 升级 YOLO 模型至更高效版本(如 YOLO-NAS),提升推理帧率。
- 开源所有硬件设计(3D 模型、PCB 原理图)及软件代码,便于社区复刻与改进。
结语
从一块开发板、若干模块到一台功能完整的智能终端,Mirror-Mirror 体现了软硬件结合的设计思路。它既是一个实用工具,也是一个展示 DIY 可能性的平台。所有设计文件及软件配置将陆续在 GitHub 开源,欢迎有兴趣的开发者关注与参与。如果你有任何问题或建议,欢迎在 GitHub 上提交 issue 或加入讨论群。
Comments NOTHING